本文作者:立创开源硬件平台 OSHWHub 用户@KJ,禁止商用,未经许可禁止转载,点击查看原文章
我做了一个智能AI音箱,主要就是将音箱连接ChatGPT,与之对话,充当语音助手。还能借助ChatGPT函数调用功能,控制实体设备。

智能AI音箱做了两个版本,以下是版本对比:
ESP32版:小巧,成本低。
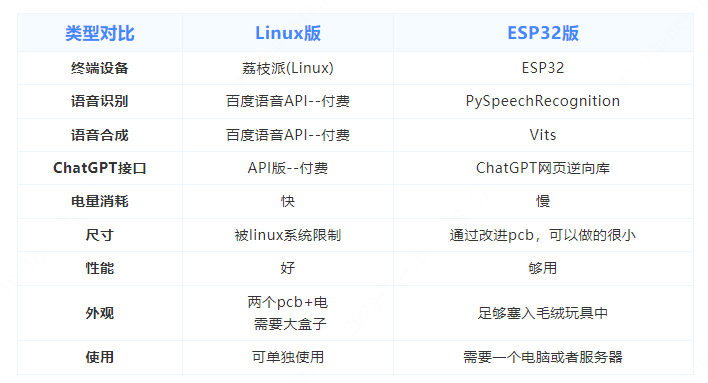
第一版可以通过软件升级达到第二版的所有效果。如何实现“智能对话”效果?下滑即可学习~两种版本都有教程!
03、Linux版
硬件部分

音频原理图
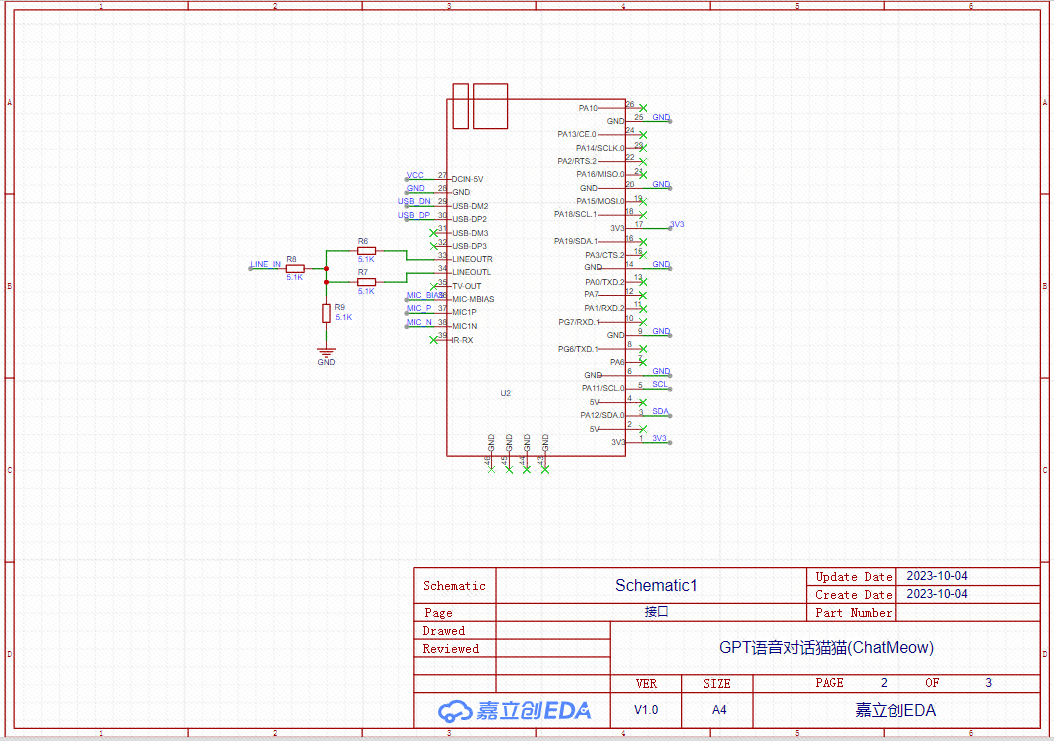
接口原理图
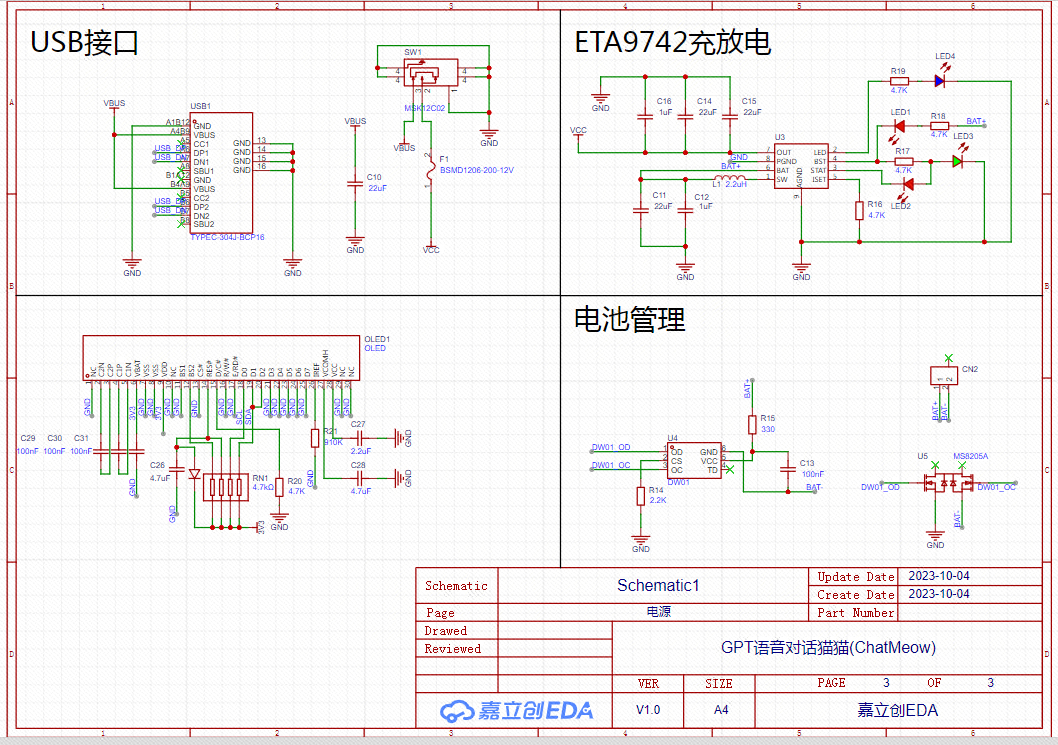
电源原理图
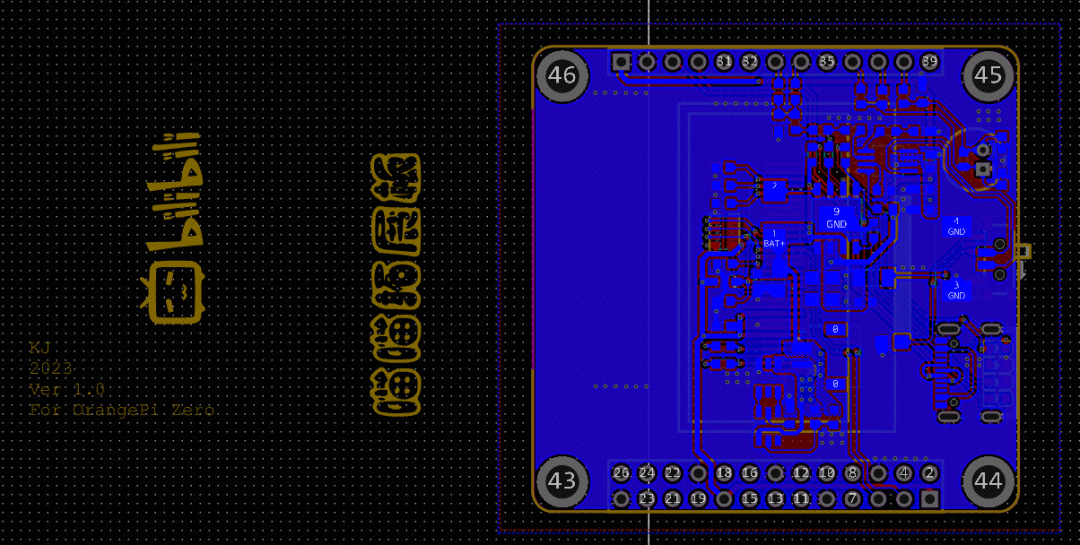
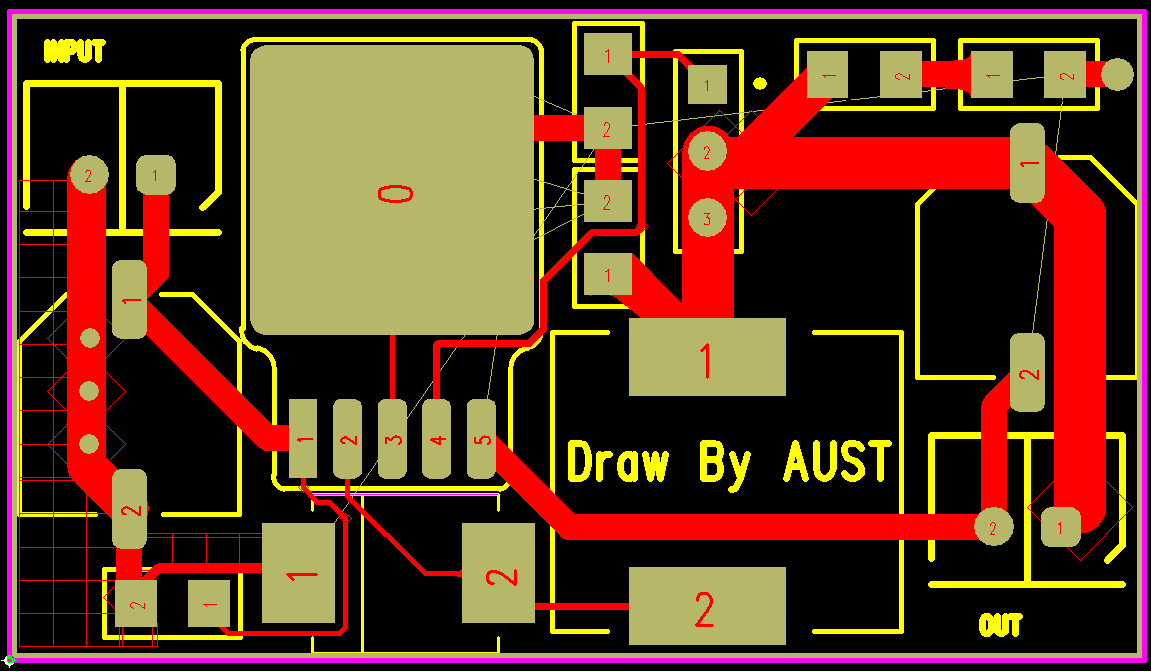
PCB图
代码仓库入口

git clone https://github.com/meowkj/chat-meow.git && cd chat-meow
或者使用准备好的Docker镜像(测试):docker pull kjqaq/chatmeow

python3 mian.py
docker run --itd -v .:/chat --privileged -itd kjqaq/chatmeow
第一步:环境准备

使用Vue3框架简单快速构建了一下页面。
第二步:克隆代码仓库
git clone https://github.com/ChatMeow/chat-meow-ui.git cd chat-meow-ui
pnpm run serve

ESP32原理图

POWER原理图
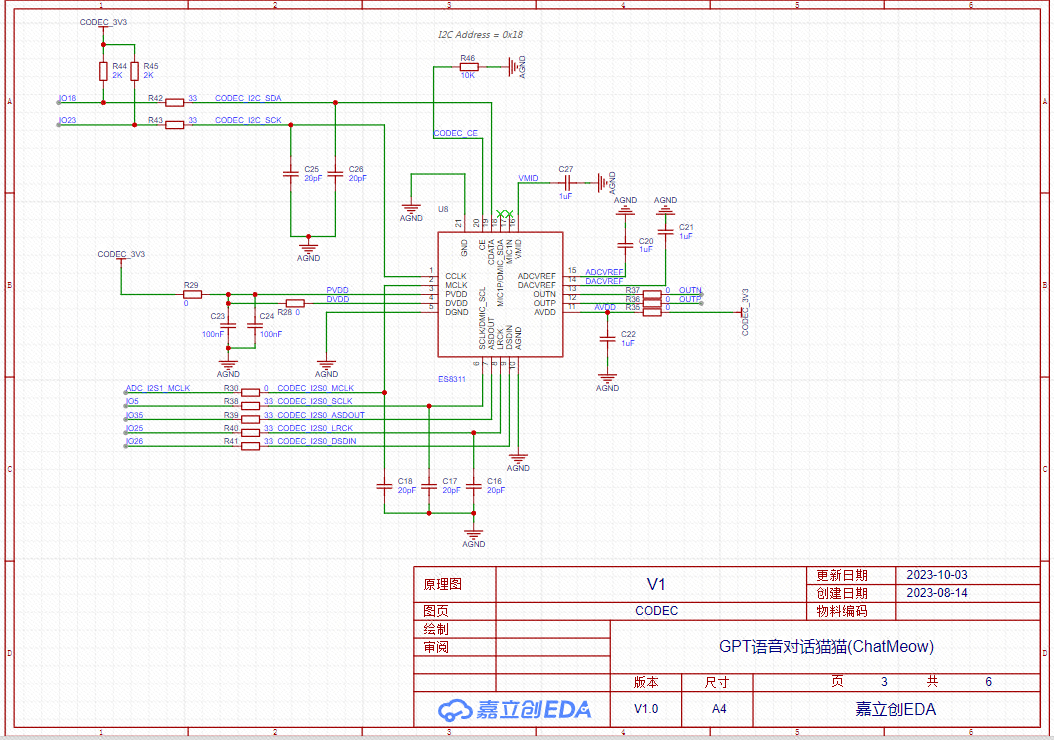
CODEC原理图
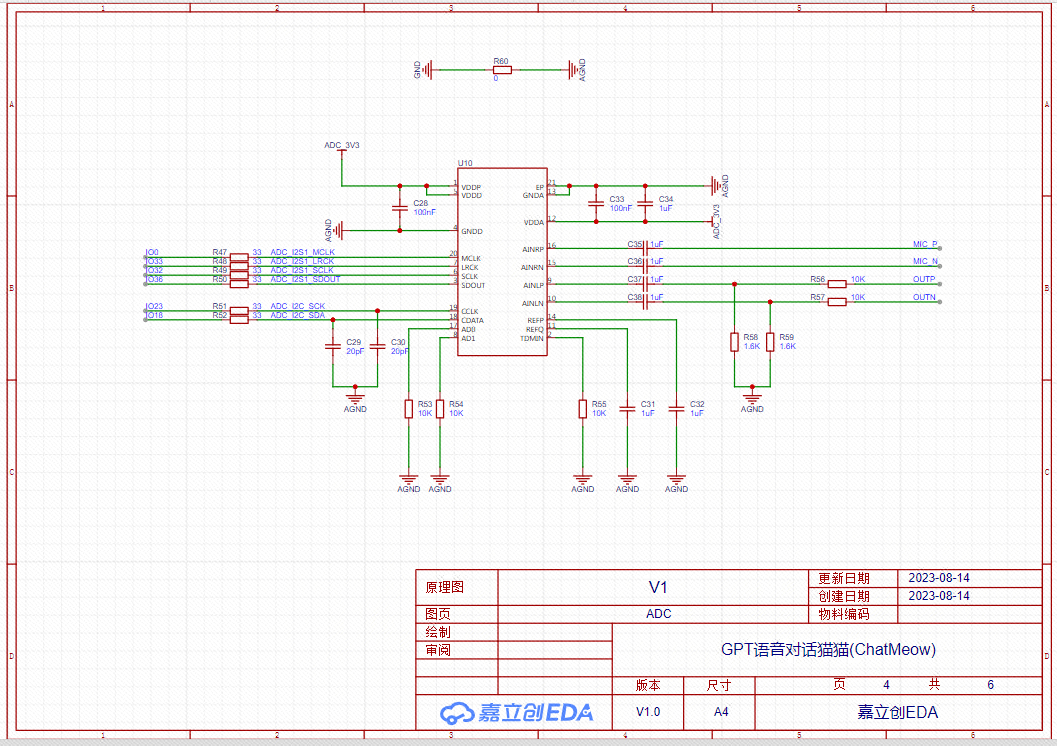
ADC原理图

MIC_PA原理图
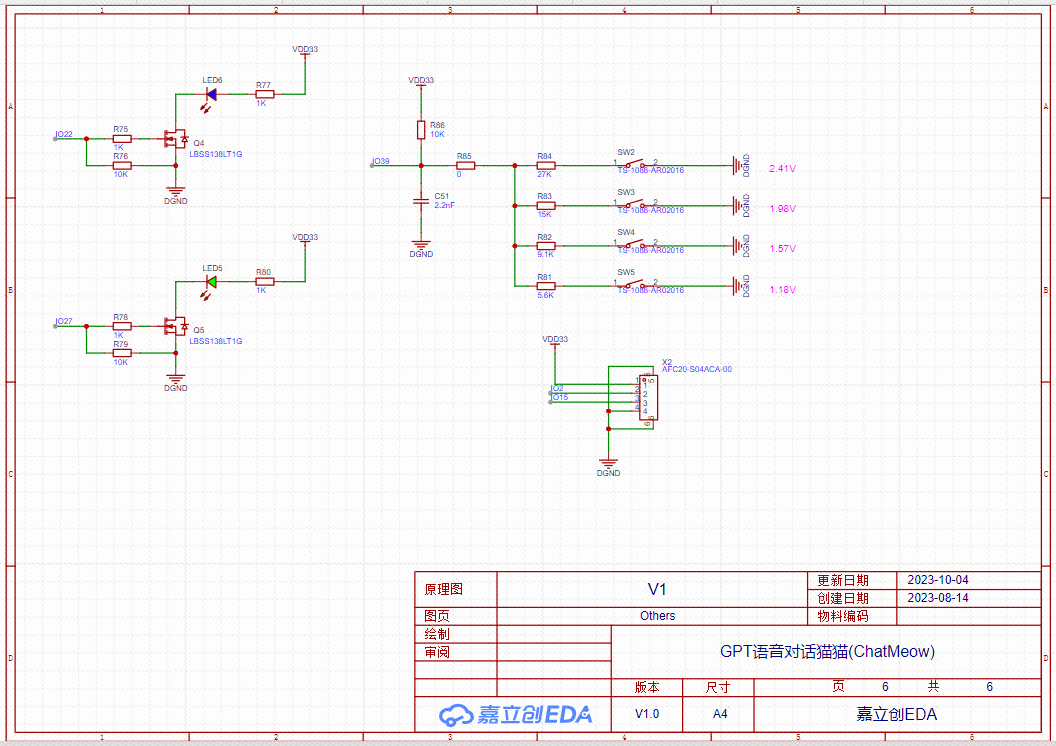
Others原理图

PCB图(点击进入嘉立创EDA编辑器打开)

PCB实物图&彩色丝印3D预览图
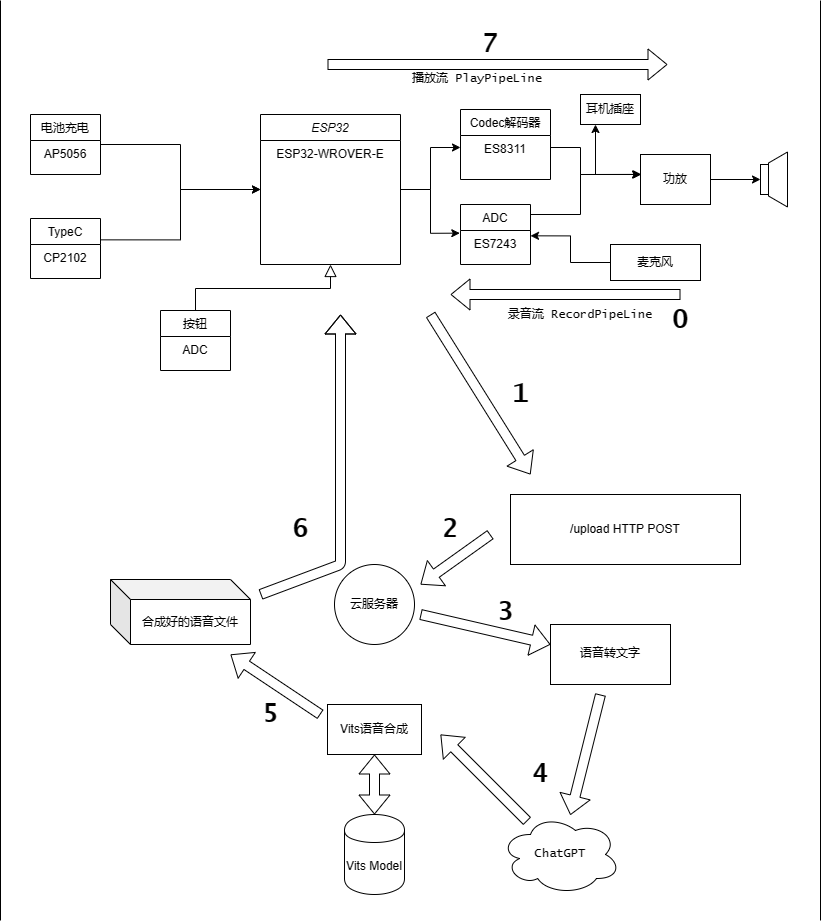
ESP32版结构流程图
这个版本由于ESP32性能不足,需要一个服务端处理语音数据。故分为两个部分:
一个是服务端,一个是边缘设备(ESP32)。
未来会设计更加迷你的PCB板子。
代码仓库有两个,一个服务端的代码由Python驱动,一个是ESP32端由ESP-ADF驱动。

值得一提的是,pyopenjtalk库似乎只能在Python3.10上安装成功,此库只影响日语生成。
第一步:环境安装
克隆本项目:
git clone https://github.com/ChatMeow/chat-meow-vits.git cd chat-mewo-vits
安装环境(推荐使用虚拟环境):
pip install -r requirements.txt
如果不存在配置文件的话,第一次运行会生成配置文件:
python server.py
第二步:配置参数
需要先配置OpenAI登录信息,在文件openai.ini中。
配置access_token:
01、这是实际用于身份验证的内容喵,可以在https://chat.openai.com/api/auth/session找到
02、2周后失效
03、推荐的身份验证方法
04、如果您登录到https://chat.openai.com/,然后转到https://chat.openai.com/api/auth/session,就可以找到
或者配置email(邮箱) password(密码)字段:
只需配置access_token(推荐)或者是email&password, 如果都配置了,优先使用access_token。
你需要准备一个Vits模型文件,测试用模型可以在Release处下载,仅供参考。
模型文件(*.pth config.json)放入根目录model(可改)文件夹里面,同时需要在config.ini中填入对应的文件名称。
第三步:启动测试服务器
python main.py
第四步:开始测试服务器
01、开始运行后,将启动默认端口8000的服务器
02、/upload接口支持POST方法,和ESP32配置项目Server URL to send data对应
03、完成tts,vits后在static目录生成out.wav文件,和ESP32配置项目Server FILE URL to play voice对应
即将支持
01、一个网页界面来配置参数
02、支持RockChinQ大佬的free-one-api接口
ESP32端代码仓库(ESP-IDF)
仓库入口
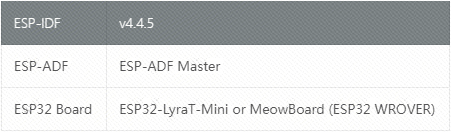
第一步:环境安装
这里使用的是 ESP-IDF v4.4,理论上支持ESP-IDF v5。
01、参考ESP-IDF编程指南安装ESP-IDF环境
02、参考乐鑫音频应用开发指南安装ESP-ADF环境(如果已配置好VSCode+ESP-IDF插件环境,在vscode命令面板 -> ESP-IDF:安装ESP-ADF 可以直接安装ESP-ADF)
克隆代码仓库:
git clone https://github.com/ChatMeow/chat-meow-esp32.git cd chat-meow-esp32
第二步:配置参数
需要先配置 Wi-Fi 连接信息,通过运行 menuconfig > Example Configuration 填写 Wi-Fi SSID 和Wi-Fi Password。
menuconfig > Example Configuration > (myssid) WiFi SSID > (myssid) WiFi Password
其次需要选择服务器地址, ,默认情况下192.168.8.5:8000需要修改为自己的服务器地址。
menuconfig > Example Configuration > Server URL to send data > Server FILE URL to play voice
第三步:编译和下载
请先编译版本并烧录到开发板上,然后运行 monitor 工具来查看串口输出(替换 PORT 为端口名称):
idf.py build
idf.py -p PORT flash monitor
第四步:开始
01、开始运行后,将主动连接 Wi-Fi 热点
02、检测是否按下REC(ESP32-LyraT-Mini)按键,如果使用喵板则需要修改按键参数
03、从麦克风读取语音上传到服务器
04、从服务器播放服务器生成好的语言
05、循环-->>>>
即将支持
01、静默状态识别自动识别是否讲话,读取语音开始循环
02、通过ChatGPT函数调用功能返回参数,接口对外输出信息,控制其他实体设备
03、更多具体的软件说明可参考代码仓库里的README内容
借助vits可以合成你喜欢角色的语音模型,测试模型使用原神纳西妲语音训练,仅供测试使用。
更多详情及附件,可从原工程查看。
本文作者:立创开源硬件平台 OSHWHub 用户@KJ,禁止商用,未经许可禁止转载